
Building your own Recommender System - Part 3/4
Let's dive into building a content-based recommender system and learn how to leverage item attributes to craft personalized recommendations tailored to individual preferences.


Welcome to the “Build Your Own Recommender Systems” series, created by Manisha Arora, Data Science Lead at Google Ads and Arun Subramanian, Associate Principal of Analytics & Insights at Amazon Ads. This blog series is designed to guide you through the foundational knowledge and hands-on techniques you need to create personalized recommendation engines. From exploring different types to implementing your own, this series is designed to give you the skills to build effective, data-driven recommendation systems that users love.
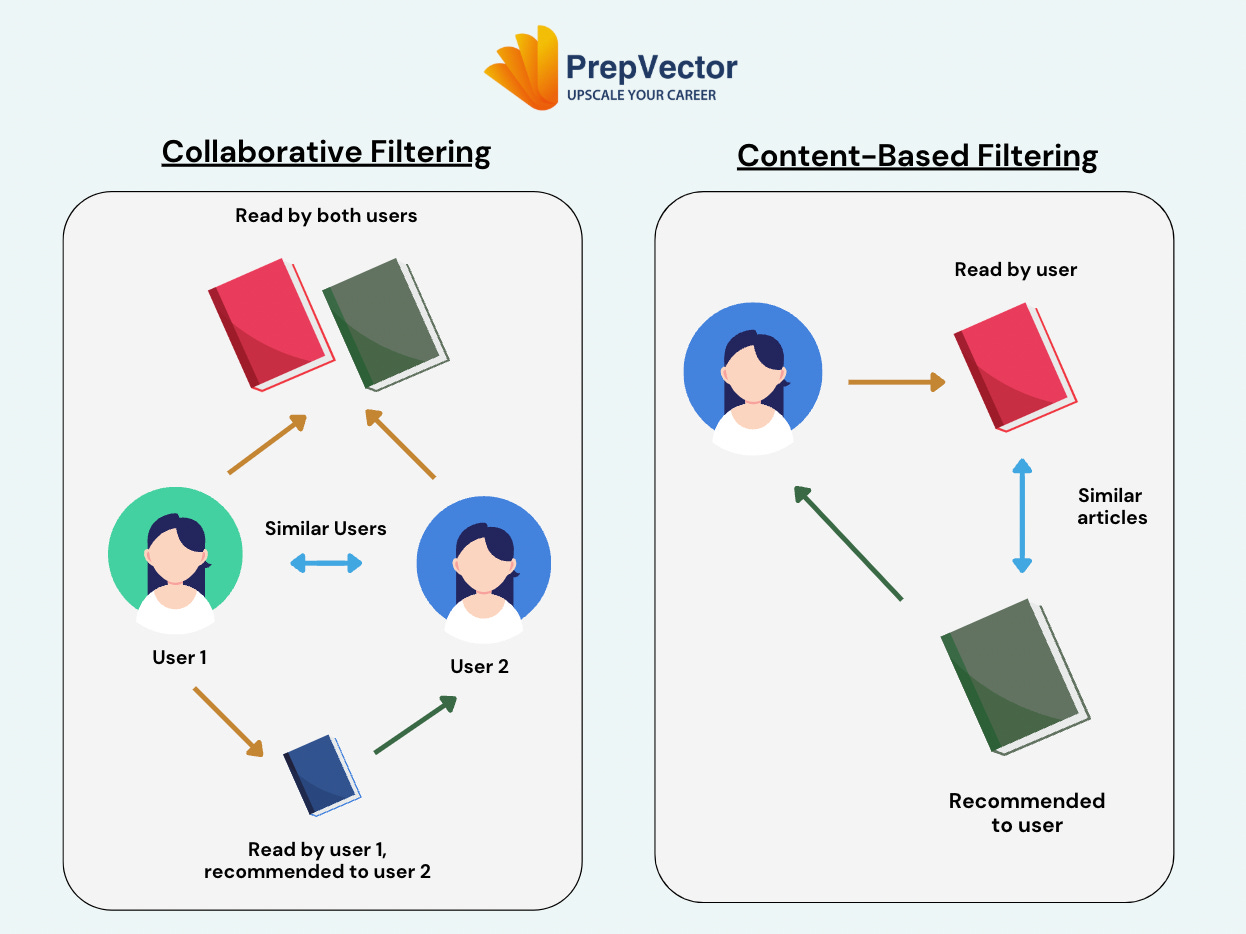
This is Part 3 of our ongoing "Building Your Own Recommender Systems" series! In the first two blogs, we explored the fundamentals of recommender systems and different evaluation techniques. Now, we turn our attention to building a content-based recommender system, a foundational approach that uses item attributes to make personalized recommendations.
Getting Started
To demonstrate a content-based recommender system, we’ll implement a simple example using Python and Pandas, leveraging a movie dataset. Although libraries like scikit-surprise don't natively support content-based methods, they do offer flexible base classes for creating custom algorithms. For simplicity, however, we’ll begin with a manual implementation. Related python notebook with complete codes are available on this GitHub repository.
Step 1: Prepare the Data
We start by loading a movie dataset into a Pandas DataFrame. This dataset includes attributes such as movie titles, genres, and release years. To prepare the data for recommendation, we’ll create a combined key column with genres and year information.




Step 2: Transform Text Data into Numerical Representation
Vectorization is a fundamental step in Natural Language Processing (NLP) that transforms text data into numerical representations. This allows machine learning models to process and understand textual information. In the context of recommender systems, we need to convert textual data into numerical representation using text vectorization so that we can calculate pairwise similarity between movies. Let’s discuss common vectorization methods before selecting one for our use case.
Types of Text Processing Vectorizers
Count Vectorizer
Converts text into a matrix of token counts.
Simple and interpretable, suitable for basic NLP tasks.
TF-IDF Vectorizer
Balances term frequency and corpus-wide importance.
Down weights common terms while emphasizing rare ones.
Word Embedding-Based Techniques
Word2Vec, GloVe, FastText: Capture semantic relationships between words.
Useful for advanced NLP tasks like text generation or translation.
Choosing the Right Vectorizer
For this example, we’ll use a simple Count Vectorizer, which works well for smaller datasets and straightforward tasks like this one.
Step 3: Implementing the Recommender
Once vectorized, we can measure the similarity between users or items, enabling the system to make accurate recommendations. Similarity metrics play a crucial role in recommender systems, particularly in content-based and memory-based collaborative filtering methods. Cosine similarity is the most common technique used to create a pairwise similarity matrix. It is calculated by taking dot products of two vectors (numerical representation of users or items) and dividing it by the product of their magnitudes. Similarity matrix allows us to find movies that are most similar to a given title. Here’s the implementation:

Step 4: Generate Recommendations
Let’s test the system by recommending movies similar to "Avatar" (2009).


The recommendations include movies with similar genres, such as Action, Adventure, and Sci-Fi, and release years close to 2009, demonstrating the effectiveness of this simple content-based approach.
Closing Thoughts
This example highlights how content-based recommender systems use item attributes to generate relevant recommendations. By leveraging techniques like vectorization and similarity metrics, even basic implementations can offer valuable insights into user preferences.
Next up in this series, we’ll explore collaborative filtering techniques, which go beyond item attributes to incorporate user behavior and interactions. Stay tuned!
If you're following along with the series, let us know what you think about content-based systems or what specific topics you'd like us to cover in future posts. Let's keep building!